Learn how to analyze your data with trust
Reading time: 10 minutes.
Topic: This blog motivates why I started a new venture dedicated to education in data analysis and data science.
Content: When searching for courses in Statistics, Data Analysis, or Data Science online, you'll find a multitude of results. So, you might ask: What is the added value of starting a business that brings even more courses on these topics?
In this post, I will elaborate on what distinguishes our approach from the commonly used approaches.
Set the stage: What do you need to get a driver's license?
Think a moment about getting your driver's license. Most likely, the driving test will have focused on skills needed to drive safely and responsibly, such as knowledge of the traffic rules, proper vehicle operation, and correct responses to various traffic situations. Typically, you were not asked to solve engine problems or other issues under the hood because those problems fall under the expertise of technicians.
That said, you were probably encouraged to have some basic knowledge about vehicle maintenance and to know how to recognize issues. If a dashboard indicator warns you that the pressure of the tire on the right rear has fallen below the minimum, you will probably make a stop at a gas station eventually and fix it. Or, if the oil indicator starts blinking that no motor oil is left, you will probably park your car right away and get assistance to fill it up (or fill it up yourself, if you feel comfortable enough to do a little work under the hood).
In short, you can get from A to B safely and responsibly without having to know anything of what happens under the hood. As long as you monitor the dashboard and take appropriate action, you are good to go.
Do you need to have a look under the hood if your goal is to answer business or research questions?
Now let me share a personal experience with you. In the late '80s, I taught my first Statistics course as an Assistant Professor, to first year students at the faculty of Psychology. We started off with Probability Theory, that is topics like set theory, probability spaces, random variables, and distributions, which took us a few months. The next months were dedicated to statistics, delving into numerous formulas.

Would a formula help in analyzing your data?
Now, the deeper we went into the formulas, the less students grasped the fundamental concepts. It became challenging for them to see the forest for the trees. And above all, such an approach certainly did not make students enthusiastic for statistics or research. In short, this approach felt much like demanding knowledge of everything under the hood, with the ultimate result that many students were demotivated, missed understanding, found it very hard to pass the exam, and, last but not least, were not able to translate or apply what they had learned to research problems. (Disclaimer: for students Mathematics or Econometrics it might be very relevant to have a thorough look under the hood, but for students Psychology, no.)
The crucial question is: what are the minimal requirements to analyze data safely and responsibly?
A few years later, I transitioned from my role at the university to a position at a company providing statistical products and service solutions. Now, in a business setting, time is money, and the faster learners grasp the topics the better. Consequently, the crucial question became identifying the minimal requirements for analyzing data responsibly. So, what do you need to know and understand about statistics and your data to yield interpretable results and answer business questions?
Clearly, you need to understand the type of variables you are dealing with.
Consider, for example, a survey inquiring about people's REGION (four regions), POLITICAL PREFERENCE (three values, left to right), AGE IN YEARS, and INCOME IN DOLLARS, depicted here.
Here, we have a few, say, "categorical" variables (GENDER, REGION, POLITICAL AFFILIATION) and a couple of, say, "continuous" variables (AGE, INCOME). The variable ID serves as a mere identifier.

A dataset of cases (or records) in the rows by variables in the columns. Tradionally, because typing codes is faster than typing texts, the categorical variables are encoded. For example, code 1 for GENDER might represent a woman.
Now, when you have 1,000 respondents and you want to summarize the data, you most likely won't report that 'the mean REGION is 2.7,' since that number is not informative. On the other hand, a statement like 'the mean AGE is 38.9' makes sense. The idea that you should adopt different approaches depending on the type of variables involved in the analysis is quite intuitive. However, it's interesting to observe that this very intuitive notion gets lost somewhere down the road.
For example, we might ask ourselves whether there is a relationship between the variables in our dataset. You might think that this is about running a Correlation procedure because 'relationship' and 'correlation' are pretty much the same in daily language. Running the Correlation procedure produces the table on the right.
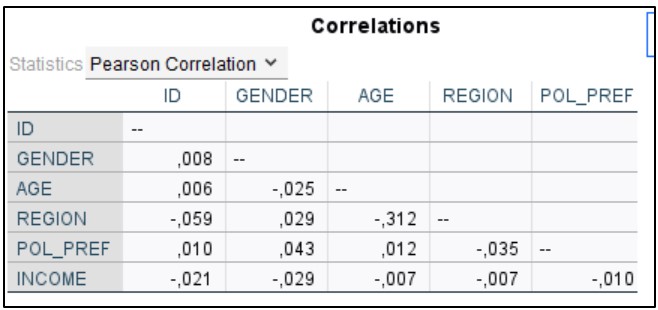
Can we interpret these correlations?
Interestingly enough (and actually quite disappointing), most statistical software does not give you a red flag when you request a statistic that is not appropriate given the type of variables; the software just computes it. In other words, the mere fact that a statistic is computed does not necessarily imply that the number makes sense. For example, since correlation is appropriate for continuous variables only, calculating the correlation between REGION and INCOME does not make any sense.
Identifying the type of your variables, a very intuitive notion, is a fundamental requirement to successfully analyze your data. It drives the choice of the analysis method; you handle variables like REGION differently than you do for INCOME. More generally, there are only a few general, intuitive guidelines to analyze your data safely and responsibly; no math, probability theory, or linear algebra required! With a good understanding of fundamental concepts, you will be able to master many topics, such as machine learning models.
Can ChatGPT help out?
In analyzing data, we might wonder if ChatGPT can be of any assistance. If so, that would further eliminate the need to learn Math, etcetera.
Are REGION and POLITICAL AFFILIATION related?
Question: What statistical procedure should I run if I would like to know if REGION and POLITICAL AFFILIATION are related?
ChatGPT: To determine if there is a relationship between two categorical variables like REGION and POLITICAL AFFILIATION, you can use the chi-square test for independence. The chi-square test is appropriate when you have categorical data ... (followed by a step-by-step guide which gives all details, including the formula of computing the Chi-square statistic, how to statistically test a hypothesis, and a note about the assumptions that must be met to use the Chi-square test).
ChatGPT also suggests creating a crosstabulation table of the two variables. However, it does not tell how we can get more insight in the relationship. For that, we would request specific percentages. So, we ourselves need to understand what percentages make sense in this situation (maybe it will become clear if you tweak the prompt long enough).
Are AGE and INCOME related?
We are not interested in the technical details (of how to compute the statistic, how to test hypotheses), but we sure want to know about the assumptions and cautions.
Question: What statistical procedure should I run to see if INCOME and AGE are related? Do not give technical details in your answer but list the assumptions and cautions.
ChatGPT: To explore the relationship between INCOME and AGE, you should use correlation analysis. Here are some assumptions and cautions to consider... (followed by a list of three critical assumptions and seven cautions).
Quite impressive! That said, looking at the list of assumptions (it comes up with linearity, normality, and homoscedasticity, and I would add independence of cases to that), you should have an understanding what these assumptions entail. The same for the cautions; for example, it warns for outliers, so you should understand how outliers can affect the correlation. (Same, by the way, for influential points, a caution that is not mentioned by ChatGPT.)
How to predict INCOME from AGE and REGION?
Now let's see if ChatGPT "knows" how to deal with a mix of categorical and continuous fields,
Question: What statistical procedure should I run to predict INCOME from AGE and REGION?
ChatGPT: To predict INCOME from AGE and REGION, you can use a regression analysis. Adding to that in the step-by-step guide: Since REGION is a categorical variable, you need to convert it into a format suitable for regression analysis. One common approach is to use dummy variables. Each region becomes a binary variable (0 or 1). For k regions, you typically create k-1 dummy variables to avoid the "dummy variable trap".
ChatGPT "knows" that we need to do something extra to include the categorical variable REGION in the analysis, great!! Computing "dummy variables" is the key to it. However, the answer might cause some confusion because it first suggests creating a dummy variable for each of the regions, but in the next sentence it tells you that you can do without one of those. It would help here to have some background in what dummy variables are and understand the rationale of creating "dummy variables" and the "dummy variable trap", which can be explained in 5 minutes.
Observations using ChatGPT
Interestingly enough, the answers of ChatGPT are in terms of the type of the variables in the analysis ("categorical", "continuous"). Starting off from variable types it arrives at the appropriate univariate, bivariate, or multivariate procedure. (Univariate: about one variable; bivariate: the relationship between two variables; multivariate: the relationship between more than 2 variables - Machine Learning models belong to this category.)
Another observation is that ChatGPT comes up with a step-by-step guide that gives you lot of details about the specific statistical test that is appropriate for the question and types of the variables involved. This is where a lot distributions come in. However, you could abstain from those details once you grasp the underlying idea that forms the basis of all statistical tests. Testing hypothesis is a very intuitive matter, which you should not complicate by a lot of technical details such as the specific distribution that is used.
We examined only a few examples of questions where ChatGPT does a great job. With that said, the answers might require validation. Also, ChatGPT might not pick up that you sometimes need to run other procedures first, like first removing redundant information from a set of variables prior to clustering cases.
We examined only a few examples of questions where ChatGPT does a great job. With that said, the answers might require validation. Also, ChatGPT might not pick up that you sometimes need to run other procedures first, like first removing redundant information from a set of variables prior to clustering cases.
To have a little background in data analysis or statistics will help much to validate and complement ChatGPT's answers. For that, you need to understand the basics, not Math (the motivtion why you would Math, Probability Theory, Linear Algebra). That is even more true because you can spend an hour of your time only once, and there are many more skills to master to become a succesful data analyst or data scientist, it's not only about Machine Learning models. Skills include: clear and timely communication, prepare data efficiently (data preparation makes up 80% of a project), domain knowledge, dashboarding, and story telling, In conclusion, embrace ChatGPT, or other AI tools, to guide you in your analyses, but handle it with care. You will need a little more background knowledge and understanding to get the most out of it. This will take an investment of weeks rather than years.
Our vision: Everyone (!) can become a successful data analyst or data scientist
Considering that delving deep into technical details under the hood doesn't significantly enhance understanding, and given the prevalence of AI and automated tools, we believe that the requirements for a curriculum to train data analysts or data scientists should differ substantially from the current mainstream in the market. We firmly assert that you don't need to be a mathematician or a statistician to thrive as a successful data analyst or data scientist. Besides, our curriculum has sifted through such technical knowledge and translated it already into real-life scenarios. We fully embrace AI tools, leverage automated modeling options, and offer an intuitive, accessible, pragmatic, and practical approach. Our focus on concepts ensures that your journey as a data analyst or data scientist is not only safe but allows you to perform your job responsibly.
Our vision: Master concepts first before going into coding
A key differentiator is also our belief that mastering concepts and becoming proficient in typical data preparation issues, algorithms, and model evaluation measures should precede coding with tools like Python or R. When you begin, it's beneficial not to be burdened by coding intricacies, interpreting vague error messages, and the like. Instead, a graphical interface becomes your best friend. Even if your ultimate goal is to code, we are confident that you'll code much faster after mastering the concepts. Thus, commencing with a graphical interface will save you more time in coding than you might lose initially by familiarizing yourself with the graphical interface. To illustrate, let's explore two examples.
Example 1: Compare group means (IBM SPSS Statistics)
First, suppose we want to statistically test the relationship between GENDER (code 0 for"Man", code 1 for "Woman") and INCOME. We need a test that is suited for a categorical variable on one side and a "scale" variable on the other. Now when the categorical variable defines two groups, the T-test is appropriate (well, appropriate if we make a few more assumptions). In, for example, IBM SPSS Statistics the path in the menu to the T-Test (named Independent Samples T-test) is Analyze > Compare Means > Independent Samples T Test, which tells you that the test is about comparing means, here the mean INCOME for men to the mean INCOME for women.
The Test Variable(s) box lists the variables for which you want to compute the mean, while the Grouping Variable and specified values define the groups to be compared. Help is just one click away if needed. The analysis takes at most one minute, and there's no need to worry about misspellings or typos. The next step involves interpreting the output. Enthusiastic learners can explore various avenues from here, investigating additional relationships (such as educational differences between groups that may explain differences in mean income).
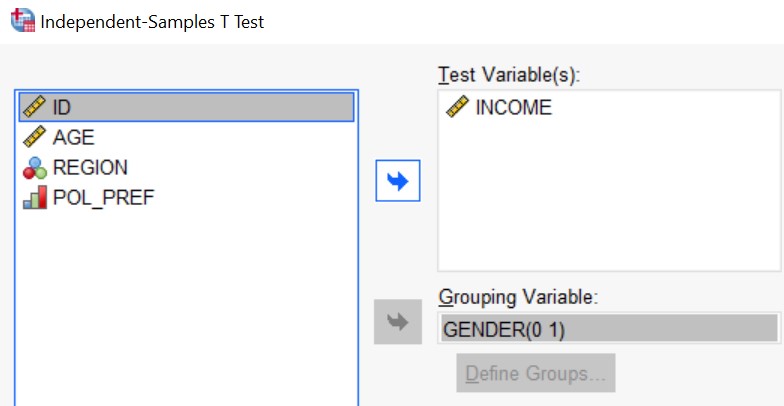
Compare one group mean to another: the Independent-Samples T Test (IBM SPSS Statistics)
Example 2: Build and apply a Machine Learning model (IBM SPSS Modeler)
The next example involves a telco provider, where the task might be to select the 1,000 customers most at risk of canceling their subscription (so they can be targeted, for example, in a campaign). A graphical interface allows you to construct a 'flow' that builds a model on historical data and applies that model to the current customers.
The figure first imports a dataset containing historical data. The dataset is then wrangled, creating both a training and test set. The XGBoost algorithm is applied to the training data to identify customer groups with high cancellation rates. The result is a model, which is evaluated against the test set. If the model proves satisfactory, it can be used to 'score' current customers, the lower branch of the stream.
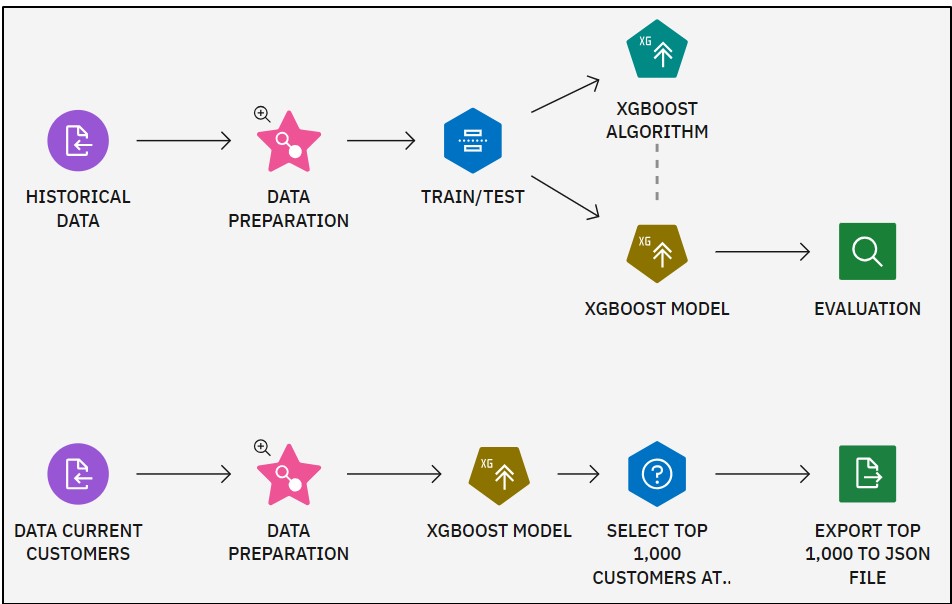
Creating this flow takes a fraction of the time needed to write code for the same task. More importantly, in the context of getting familiar with ideas and concepts, the flow reveals many interesting aspects, such as the distinction between 'algorithm' and 'model,' 'training' versus 'test' data, and the process of evaluating a model, among others. It may also raise questions that enhance your understanding, like why there is no XGBoost algorithm in the lower branch.
Conclusion
We are convinced that anyone who is motivated can become a data analyst or data scientist, and that you don't have to have a scientitic background. Instead, we opt for an intuitive, user-friendly, pragmatic, and practical approach. Build your knowledge and understanding with these principles, and enhance it further with the integration of AI and automated tools, enabling you to analyze data safe and responsibly, much like what you did when you started driving.
Thank you and happy learning!
Geef een reactie